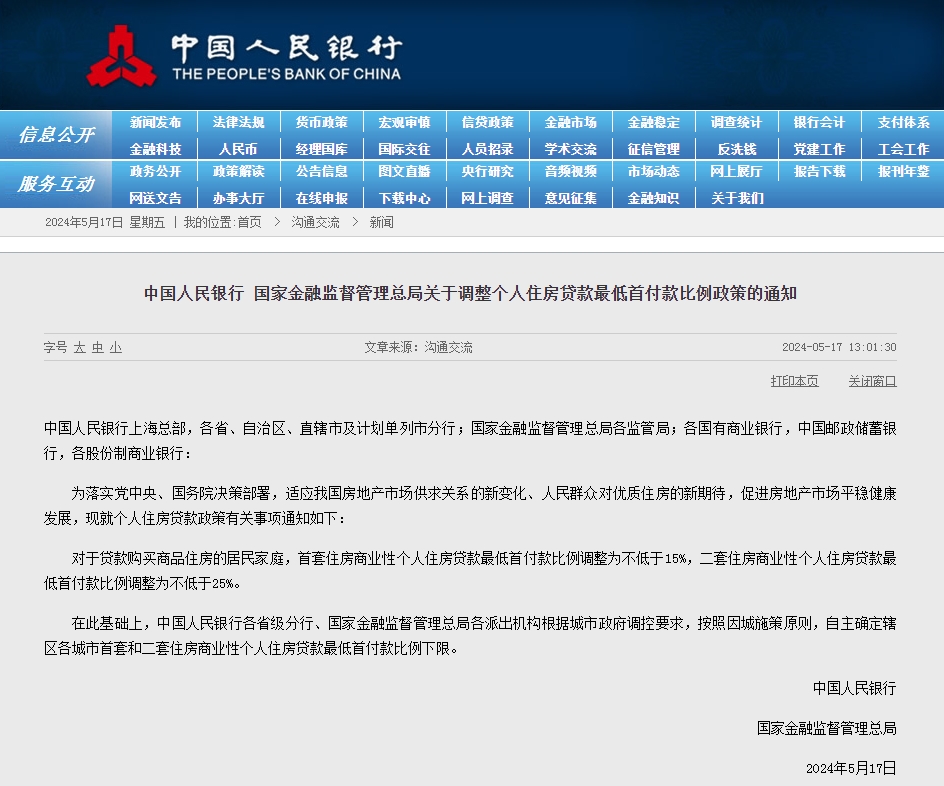
 (資料圖片)
(資料圖片)
心智理論對(duì)人類(lèi)社交互動(dòng)十分重要,是人類(lèi)溝通交流和產(chǎn)生共鳴的關(guān)鍵。之前的研究表明,LLM這類(lèi)人工智能(AI)可以解決復(fù)雜的認(rèn)知任務(wù),如多選決策。不過(guò),人們一直不清楚LLM在心智理論任務(wù)(被認(rèn)為是人類(lèi)獨(dú)有的能力)中的表現(xiàn)是否也能比肩人類(lèi)。
此次,德國(guó)漢堡—埃彭多夫大學(xué)醫(yī)學(xué)中心團(tuán)隊(duì)選擇了能測(cè)試心智理論不同方面的任務(wù),包括發(fā)現(xiàn)錯(cuò)誤想法、理解間接言語(yǔ)以及識(shí)別失禮。他們隨后比較了1907人與兩個(gè)熱門(mén)LLM家族——GPT和LLaMA2模型完成任務(wù)的能力。
團(tuán)隊(duì)發(fā)現(xiàn),GPT模型在識(shí)別間接要求、錯(cuò)誤想法和誤導(dǎo)方面的表現(xiàn)能達(dá)到甚至超越人類(lèi)平均水平,而LLaMA2的表現(xiàn)遜于人類(lèi)水平;在識(shí)別失禮方面,LLaMA2強(qiáng)于人類(lèi)但GPT表現(xiàn)不佳。研究人員指出,LLaMA2的成功是因?yàn)榛卮鸬钠?jiàn)程度較低,而不是因?yàn)檎娴膶?duì)失禮敏感;GPT看起來(lái)的失利,其實(shí)是因?yàn)閷?duì)堅(jiān)持結(jié)論的超保守態(tài)度,而不是因?yàn)橥评礤e(cuò)誤。
研究團(tuán)隊(duì)認(rèn)為,LLM在心智理論任務(wù)上的表現(xiàn)堪比人類(lèi),不等于它們具有人類(lèi)般的“情商”,也不意味著它們能掌握心智理論。但他們也指出,這些結(jié)果是未來(lái)研究的重要基礎(chǔ),并建議進(jìn)一步研究LLM在心理推斷上的表現(xiàn),以及這些表現(xiàn)會(huì)如何影響人類(lèi)在人機(jī)交互中的認(rèn)知。
關(guān)鍵詞:

















 營(yíng)業(yè)執(zhí)照公示信息
營(yíng)業(yè)執(zhí)照公示信息